
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 제주코딩베이스캠프
- 자바스크립트
- 이벤트루프
- 프론트엔드
- VAR
- 배열
- 내일배움카드
- react
- array
- 타입스크립트
- 멋사
- 화살표함수
- for문
- 비동기
- 리액트
- 코딩
- Let
- CSS
- JavaScript
- useState
- 개발자
- 멋쟁이사자처럼
- 네트워크
- 웹개발
- 반복문
- SS
- likelion
- 국비지원
- 메소드체이닝
- frontend
- Today
- Total
Ch.Covelope
자료 구조 / data structure , 자료구조란 본문

자료구조란
- 자료 구조는 데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령을 의미한다.
- 자료구조는 서비스나 어플리케이션에서 필요한 데이터를 메모리에 어떻게 구조적으로 잘 정리해서 담아두고 관리하고 최종적으로 가장 효율적인 방식으로 필요한 데이터를 빠르게 접근하고 필요한 수정/삽입/삭제 를 할 수 있도록 도와준다.
- 한정적인 자원에서 메모리를 효율적으로 사용하기 위해서 필요하다
- 모든 목적에 부합하는 자료구조는 없으며 필요 목적에서 효율적인 자료 구조를 선택하여 효율을 높일 수 있다.
자료 구조는 알고리즘과 밀접한 관계 가 있는데
이유는 보통 자료구조가 선택되면 그에 적용할 알고리즘이 거의 명확해진다.
예) 배열이라면 반목문을 사용한 알고리즘 이라던지
즉 자료 구조가 효율적인 알고리즘을 사용할 수 있게 함으로 자료구조와 알고리즘은 밀접한 관계에 있다.
참고
- 알고리즘은 프로그램 명령어들의 집합 이라고도 한다.
- 프로그램은 특정 문제를 해결하기 위한 처리 방법과 순서를 기록한 명령어들의 모음(알고리즘).
- 이 프로그램이 실행되기 위해서는 메모리에 올릴 데이터가 필요하며 이 데이터들을 담아내는 방식은 자료구조이다.
넓은 의미로 자료구조 + 알고리즘 = 프로그램이다.
특징
- 효율성 - 상황과 목적에 맞게 적절한 자료구조를 선택함으로 데이터 관리가 가능하다.
- 추상화 - 복잡한 자료, 모듈, 시스템 등으로부터 핵심적인 개념만을 간추려 낸다.
- 재사용성 - 자료구조를 이용하여 데이터를 처리할 경우 해당 자료구조의 인터페이스만 이용하여 데이터를 처리하도록 함으로 모듈하가 가능하다.
자료구조 참고 이미지

자료구조에는 선형(Liner)과 비선형(NonLiner)으로 나눠진다.
선형
- 자료를 구성하는 원소들을 하나씩 순차적으로 나열시킨 형태
- 앞,. 뒤 간 1:1의 관계로 배열과 리스트가 대표적이며 스택과 큐도 이해 해당한다.


선형 구조
배열(Array)
데이터를 나열하고, 각 데이터를 인덱스에 대응해 주며 인덱스로 데이터로 접글 할 수 있도록 구성된 데이터 구조
- 연속된 메모리 공간에 순차적으로 저장된 데이터 모음이다.
- 대부분의 언어에서 동일 타입의 데이터를 순차적으로 저장한다.
- 메모리 상에 순차적으로 저장되기 때문에 데이터의 순서가 있고 index로 접근 가능하기 때문에 빠르게 접근 가능하다.
- 배열은 부가정보 없이 데이터만 저장하기 때문에 공간 낭비가 적다.
- 배열의 크기를 설정해줘야 한다(언어마다 다름 자바스크립트 X)
- 추가/삭제 시 조건에 따라 모든 데이터가 재배치된다.
참고
자바스크립트의 배열은 자료구조에서 말하는 배열과 같은 의미의 배열이 아니다, 자바스크립트의 배열은 배열을 비슷하게 만든 객체라고 보면 된다.
보통 배열의 데이터는 같은 타입을 가지며 순차적인 메모리 공간을 가지는데 자바스크립트의 배열은 객체 이기 때문에 어떠한 값도 담을 수 있다.
자바스크립트 배열은 인덱스를 프로퍼티 키로 갖으며 length 프로퍼티를 갖는 특수한 객체이다.
자바스크립트 배열은 해시 테이블로 구현된 객체이므로 인덱스로 배열 요소에 접근하는 경우, 일반적인 배열보다 느릴 수 있지만 특정 요소를 탐색하거나 요소를 삽입 또는 삭제하는 경우에는 일반적인 배열보다 빠른 성능을 기대할 수 있다.
- 일반 배열은 메모리상 순차적
- 해시 테이블로 구현된 배열은 해시함수로 해싱된 값의 인덱스 값을 메모리 주소로 사용하기 때문에 순차적인 메모리 할당을 보장할 수 없다.
연결리스트(Linked List)
https://velog.io/@kimkevin90/Javascript를-이용한-Linked-List-구현
Javascript를 이용한 Linked List 구현
Javascript에서 연결리스트는 객체를 통해 구현할 수 있다.아래 예시는 두개의 객체를 next로 연결하여 Linked List의 기본적인 구조를 보여준다연결리스트의 핵심은 node이며, node는 data를 담는 data field
velog.io
연결리스트는 배열과 달리 메모리상에 index에 의한 물리적 배치가 아닌 노드를 생성 후 해당 노드의 포인터에 의해 다음 노드를 연결한다.
그렇기 때문에 추가/삭제 시 데이터 구조를 재배치하지 않아도 된다.
1. 단일

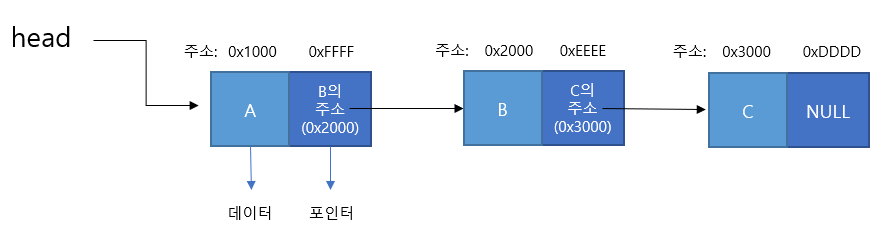
노드를 단위로 한다. 노드는 데이터와 다음 노드를 가리키는(포인) 참조값으로 구성된다.
맨 앞의 노드를 헤드(head), 끝에 위치한 노드를 테일(tail)이라 한다.
- 리스트의 길이가 가변적이라 미리 길이를 정해야 하는 배열의 단점을 커버할 수 있다.
- 삭제나 추가가 O(1) 시간에 가능하다. (데이터가 추가/삭제되면 해당 노드의 포인터만 변경된다) 배열은 재배치해야 된다.
2. 이중
단일 연결 리스트는 포인터를 다음 노드만 가리킨다. 하지만 이중연결 리스트는 두 개의 포인트로 이전 노드와 다음 노드를 가리킨다.
3. 원형
단일 연결 리스트의 테일에 포인터가 추가된 형태로 테일의 포인터는 헤더를 가리켜 원형이 되도록 한다.
https://fomaios.tistory.com/entry/DataStructure-연결리스트에-대해-알아보자Linked-List
[Data Structure] 연결리스트에 대해 알아보자(Linked List)
안녕하세요 Foma👟 입니다. 오늘은 연결리스트에 대해서 알아보려고 하는데요. 얼마 전에 2021 카카오 인턴쉽에 출제되었던 "표편집" 이라는 문제를 풀게 되었는데 해당 문제는 연결 리스트를 꼭
fomaios.tistory.com
스택과 큐
- 실제 프로그래밍 언어들에서 존재하지 않은 상상의 자료구조이다. 즉 추상적 자료구조 라고 한다. - Abstract Data Type
- 스택과 큐는 일종의 규칙이다.
- 자료구조의 방법이 코드로 정의된 것이 아니라. 그 구조의 행동 양식만 정의되어 있다.
- 해당 구조의 규칙을 이해하면 직접 스택과 큐의 자료구조를 구현할 수 있다.
스택(stack)

스택은 예를 들어 배열이 수직으로 쌓여 있다고 생각하면 된다.
하지만 이 배열에선 요소를 추가하거나 삭제할 때 맨 위부터 순차적으로 할 수 있고
그래서 후입선출 LIFO (last in first out)의 특징을 가지고 있다.
스택의 적용
- 웹 브라우저에서 뒤로 가기에 사용되는 자료구조는 스택이다.
- 뒤로 가기를 누른다는 것은 웹페이지 히스토리 스택의 맨 위에서 한 페이지를 가져가는 것
- 우리가 작업을 하다가 control + z 를 뒤로 가기를 한다는것도 스택이다.
- 우리가 작업하는 것 들을 스택에 쌓다가 뒤로가기를 할 때 맨 위에서 요소를 가져온다.
큐(Queue) 한큐에 가자

큐는 우리가 어딘가 줄을 선다고 생각하면 되는데 줄에 맨 앞부터 먼저 들어가고 줄에 마지막이 마지막에 들어간다고 이해하면 된다.
큐도 역시 배열로 예로 들어 가장 먼저 큐에 입장한 요소가 가장 먼저 큐에서 나가는 요소가 된다.
이를 FIFO(first in first out) 선입 선이라고 한다.
큐의 적용
- 이메일 전달 혹은 푸시 알림 기능, 선착순 쇼핑몰, 콜센터 등 순서대로 작업을 처리하는 일들이다.
해쉬 테이블 - Hash Table
해쉬 테이블은 key - value 시스템을 이용해서 자료를 정리한다. 예) 사전
해쉬 테이블에는 array 구조가 있다. 모든 해쉬 테이블 값들은 배열처럼 내부 구조의 인덱스를 가지고 있다. 하지만 배열보다 빠른 이유는 해쉬 함수 때문이다.
해쉬 함수가 내가 저장하고 싶은 key를 숫자로 바꿔 버린다. 그 숫자가 해쉬 테이블의 인덱스가 된다.
- 해시테이블의 key 값을 해시함수를 사용하여 변환한 값을 index로 삼는다.
- 해시함수를 사용해 key 값을 index로 변환하는 과정을 해싱이라 한다.
해쉬 테이블을 기본적으로 O(1)의 시간복잡도를 가지지만 항상 그렇지는 않다 충돌이 생겼을 경우에는 선형 검색을 통해 값을 가져온다.
해쉬 테이블과 배열을 비교
레스토랑의 메뉴를 배열에 저장한다면
menu = [
{ name: "coffee" , price: 10},
{ name: "burger" , price: 30},
{ name: "tea" , price: 10},
{ name: "pizza" , price: 40},
]
위와 같은 모습일 텐데 여기서 피자의 가격이 얼마인지 알고 싶다면 Linear Search(선형검색)를 하면 된다.
- 각 아이템을 처음부터 마지막까지 체크 하는 방법
요소가 적을때는 상관이 없지만 수천 수만가지라면 처음부터 끝가지 검색하는데에 많은 시간이 소요 된다
그래서 이때 해쉬 테이블을 이용한다.
menu = {
coffee : 10,
burger : 20,
tea : 10,
pizza : 40
}위와 같은 해쉬 테이블 에서 pizza 가겨을 알고 싶다면 key 는 pizza 이고 value 는 40 이 된다 .
배열과 해쉬 테이블의 시간복작도를 계산하면 배열은 O(N)이며 해쉬 테이블은 O(1) 이다.
즉 Constant Time(상수 시간)이다.
해쉬 테이블에선 그 어떤 메뉴의 값을 찾더라도 소요되는 스텝이 1개 이다.
아이템을 추가/삭제 할때도 마찬가지로 O(1) 이다.
배열과 비교했을때 엄청나게 빠른 속도를 가진다.
해시 함수(Hash function)
- 해시 함수의 가장 중요한 점은 고유한 인덱스를 만드는 것이다.
- 만약 중복되는 인덱스가 발생하면 충돌로 이어진다 그래서 해시 알고리즘을 적절히 구현하는 것이 중요하다.
대표적 해시 알고리즘
Division Method:
- 숫자 key 를 테이블의 크기로 나누어 나온 나머지를 인덱스로 사용
- 이때 테이블 크기를 소수로 정하고 2의 제곱수와 먼 값을 사용하는 것이 효과가 좋다.
- 예) key 값이 23 일 때 테이블 사이즈가 7 이면 index 의 값은 2이다.
Digit Folding:
- key의 문자열을 아스키코드로 바꾸고 그 값을 합해 테이블 내의 주소로 사용한다.
- 이때 index가 테이블의 크기를 넘어가면 Division Method를 적용할 수 있다.
Multiplication Method:
- 숫자로 된 key 값 k와 0과 1 사이의 실수 A, 보통 2의 제곱수인 m을 이용해 특정 계산법의 값을 index로 사용한다. index = (K*A mod 1)*m
충돌(Collision)
해시 함수를 통해 index값을 구했을 때 중복이 생기는 충돌이 발생할 수 있다.
해결법으로 분리 연결법, 개방 주소법 등이 있다.
분리연결법(separate Chaining)
해시 충돌이 발생하여 2개 이상의 키가 중복되었을 때 동일한 버킷에 해당 데이터를 먼저 저장한 순서대로 연결 리스트, 트리등 자료 구조를 활용하여 주소를 저장하는 것이다.
해당 방법은 테이블의 확장이 필요 없고 원소를 쉽게 삭제할 수 있다는 장점이 있지만
데이터가 많아지면 동일한 버킷에 체이닝 되는 데이터가 많아지기 때문에 데이터 효율이 떨어질 수 있다.
개방주소법(Open Addressing)
추가적인 메모리를 사용하여 비어있는 해시 테이블의 공간을 활용하는 방법이다.
- Linear Probing(선형탐색)
- 현재의 버킷 index로부터 고정폭만큼 이동하여 차례대로 검색해 비어있는 버킷에 데이터를 저장
- Quadratic Probing(이차탐색)
- 해시의 저장순서 폭을 제곱으로 저장하는 방식, 예를 들어 처음 충돌이 발생한 경우 1만큼 이동하고, 그다음 충돌이 발생하면 2^2, 3^2 칸 씩 옮기는 방식이다.
3.Double Hasing Probing(이중해싱탐색)
- 해시된 값을 한 번 더 해싱하여 해시의 규칙성을 없애버리는 방식이다.
해시된 값을 한번더 해싱하여 새로운 주소를 할당하기 때문에 기존 방식보다 더 많은 연산을 하게 된다.
비선형
- 선형과 다르게 하나의 자료 뒤에 여러개의 자료가 존재할수 있는 형태이며 자료간 앞,뒤 관계가 1:n 또는 n:n 관계를 나타낸다.
트리와 그래프가 대표적이며, 계층적 구조를 나타내기에 적합하다.

트리
https://www.youtube.com/watch?v=i5yHkP1jQmo
트리는 노드로 이루어진 자료구조 이다.
트리는 그래프의 한 종류로, 방향성이 있는 비순환 그래프입니다. 루트(root) 노드를 중심으로 여러 개의 서브 트리(subtree)로 구성되어 있는데. 이러한 트리는 다음과 같은 특징을 가진다.
.
- 트리에는 사이클이 없다
- 노드들과 노드들을 연결하는 간선들로 구성되어 있다.
- 노드들은 특정 순서로 나열될 수도 아닐 수도 있다.
- 각 노드는 부모 노드로 연결이 있을수도 없을 수도 있다.
- 그래프의 한 종류로 사이클이 없는 연결 그래프 이다.
- N 개의 노드는 N 개의 간선을 가진다.
그래프(Graph)
그래프는 정점(Vertex)과 간선(Edge)으로 이루어진 자료구조이다. 정점은 노드(Node)로도 불리며, 간선은 노드와 노드를 연결하는 선이다. 이러한 그래프는 다음과 같은 특징을 가진다.
- 방향 그래프와 무방향 그래프가 존재 한다. 간선에 방향성이 있는 경우를 방향 그래프, 없는 경우를 무방향 그래프라고 한다.
- 루프(loop)가 있을 수 있다. 즉, 한 노드에서 다시 자기 자신으로 가는 간선이 존재할 수 있다.
- 두 노드를 연결하는 간선은 여러 개일 수 있다.
- 그래프에는 사이클(Cycle)이 존재할 수 있다.
그래프는 다양한 분야에서 사용된다. 예를 들어, 지도를 그래프로 표현하여 길 찾기 알고리즘을 적용할 수 있다. 또한, 네트워크 관련 문제에서도 그래프를 사용한다.
* Graph 그래프
https://www.youtube.com/watch?v=2edeT2eVFAE
참고
https://m.hanbit.co.kr/media/channel/view.html?cms_code=CMS8073601837&cate_cd=001
개발자는 반드시 자료구조와 알고리즘을 배워야 할까?
'프로그래머라면 반드시 알고리즘을 배워야 하나요?' 언젠가부터 개발자 채용 과정에서 코딩 테스트를 보는 기업이 늘어나자 이런 질문이 줄어들었습니다. 알고리즘이 취업과 직결된 이후 알고
m.hanbit.co.kr
https://roi-data.com/entry/자료구조-4-스택Stack이란-연산-구현방법
[자료구조] 4. 스택(Stack)이란? / 연산, 구현방법
이번 포스팅에서는 스택의 개념과 구조, 연산과 함께 스택을 각각 정적 및 동적으로 구현하는 방법에 대해서 정리해보았습니다. 📌 주요 개념 ✔️ 스택(Stack)이란? ✔️ 스택 vs 리스트 vs 큐 (비
roi-data.com
https://www.youtube.com/watch?v=okHGRlgR8ps
https://code-lab1.tistory.com/14
[자료구조] 해시 테이블(Hash Table) 이란? , 해시 알고리즘 , 해시 함수
해시 테이블(Hash Table)이란? 해시 테이블은 (Key, Value)식으로 데이터를 저장하는 자료구조 중 하나로 key를 통해 평균 O(1)에 value를 검색할 수 있는 자료구조이다. 해시 테이블은 Key 값을 해시함수(Ha
code-lab1.tistory.com
https://blue-ilike.tistory.com/entry/자료-구조란-데이터-구조-Data-Structure
자료 구조란? 데이터 구조란? Data Structure?
자료구조란? 대량의 데이터를 효율적으로 관리할 수 있는 데이터의 구조(집합)를 뜻한다. 자료구조의 특징 효율성 상황과 목적에 맞게 적절한 자료구조를 선택함으로써 효율적인 데이타 관리가
blue-ilike.tistory.com
https://bnzn2426.tistory.com/115
자료 구조(Data Structure) 개념 및 종류 정리
자료 구조란? 데이터 값의 모임, 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분하여 표현한 것. 예를 들어 한정된 크기의
bnzn2426.tistory.com
https://hanamon.kr/자료구조란-자료구조를-배우는-이유/
[자료구조] 자료구조란? (자료구조를 배우는 이유) - 하나몬
❗️자료구조를 배우는 이유 ✅ 데이터를 체계적으로 저장하고, 효율적으로 활용하기 위해서 자료구조를 사용한다. ✅ 대부분의 자료구조는 특정한 상황에 놓인 문제를 해결하는 데에 특화되
hanamon.kr
https://ko.wikipedia.org/wiki/자료_구조
자료 구조 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 자료구조(資料構造, 영어: data structure)는 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다.[1][2][3] 더 정확히 말해,
ko.wikipedia.org
(자료구조(data structure),배열(Array),연결리스트(LinkedList),해시테이블(hashTable),트리(tree),그래프(graph),스택(stack),큐(Queue))
Ch.Covelope
Chrys_Code_Develope.
covelope.tistory.com
'Server , etc' 카테고리의 다른 글
| RSA(암호화 알고리즘) /SSH(보안 셸) 간단 정리 (0) | 2023.06.23 |
|---|---|
| 오늘의 에러 <리액트,react 에러> (You are running `create-react-app` 5.0.0, which is behind the latest release (5.0.1)) (0) | 2022.04.29 |
| SOP(same origin policy)-동일 출처 정책,CORS(cross origin resource sharing)-교차 출처 리소스 공유 (0) | 2022.03.31 |
| 쿠키,세션,캐시 (cookie, session, cache) 간단하 (0) | 2022.03.30 |
| 프론트 엔드(front-end)가 알아야할 내용들 (0) | 2022.01.12 |



